Additional information
Additional information
DARIAH-DE has developed the following definition of research data in the context of project work:
DARIAH-DE understands all those sources / materials and results collected, written, described and / or evaluated in the context of a research and research question in the field of human and cultural sciences, and in machine-readable form for the purpose of archiving, citation and for further processing.
The purpose of this definition is to take account of the special characteristics of human-scientific research and the resulting heterogeneity of the underlying data. The individual workflows reflect in a certain way the processes within a Research Data Lifecyc as they should normally be carried out.
Minimum requirements for digital research data in the context of DARIAH-DE
In order to use the DARIAH-DE services for your own research data, your data should fulfill certain basic requirements. These are usually composed of:
- Validity
- Reliability / documentation of the creation and raising context
- Machine readability (and thus processability)
- Referencing with the information provided by the author and on legal information regarding their further use (by third parties)
Where can I get more information on research data?
DARIAH-DE would like to continuously develop the information service and provide multimedial services.
In our Youtube-Channel you will find various clips related to research data.
The DHd-Blog informs about current topics and developments.
In the bibliography Digital Humanities you will find both introductory works as well as additional titles and thematic fields.
The following external pages contain comprehensive additional information on research data:
Zusammen mit der Definition geisteswissenschaftlicher Forschungsdaten bildet der Research Data Lifecycle (Forschungsdatenzyklus) das intellektuelle Konzept hinter der zentralen Infrastruktur für DARIAH-DE. Die Repository-Infrastruktur wird so ausgebaut, dass der gesamte Research Data Lifecycle für die digitalen Geisteswissenschaften abgedeckt und ggf. erweitert werden kann.
Grundlegende Prozesse im Lebenszyklus von Forschungsdaten:
- Planung und Erstellung
- Auswahl
- Ingest / Übernahme
- Speicherung / Infrastruktur
- Erhaltungsmaßnahmen
- Zugriff / Nutzung
Die DARIAH-DE Data Federation Architecture
Die DARIAH-DE Data Federation Architecture (DFA) ist die Bezeichnung für Basisdienste die von DARIAH-DE bereitgestellt werden, um die grundlegenden Prozesse des Research Data Lifecycle abzudecken. Momentan umfasst die DFA die Indizierung und Anzeige von Forschungsdaten, die Bereitstellung von Beschreibungsschemata für Sammlungsbeschreibungen und deren langfristige Speicherung, sowie eine umfassende Suchfunktionalität für heterogene strukturierte Datensammlungen und Archive. Zudem sind spezifische Metadatenstandards hinterlegt und Crosswalks zwischen Metadaten-Schemata abgespeichert um Hilfestellung beim Mapping von Forschungsdaten unterschiedlicher Herkunft und Beschaffenheit zu ermöglichen.
Why should I license my data?
The Deutsche Forschungsgemeinschaft (DFG) advises in its "Recommendations for the safeguarding of good scientific practice" to keep primary data on "durable and secure media" in the institution which produces it for ten years. However, the traceability of scientific results is not the only way to archive data. The provision of data is at least as important as a justified claim. A free, overregional and long-term access to data raises a number of legal issues, which can be regulated by means of licenses. Among other things, they provide answers on what scientists can (or do not) do with the research data of others.
Forschungslizenzen.de
The portal „Forschungslizenzen.de“, which has been established within the scope of the DARIAH-DE project, provides an overview of research licenses and presents them in a practical way using projects from the humanities. The aim is to provide an overview, to network contacts and to facilitate the introduction into the topic.
The portal responds to two requirements, which have become clear when working in DARIAH-DE: on the one hand, the desire for the exchange of knowledge for the licensing of research data, as well as the need for clarification and consulting work regarding the corresponding decision-making processes.
The selection of the presented examples focuses on the field of digital humanities. The texts are taken from current publications on the subject, the contents are supplemented by new developments. In contributions to individual projects, the contact information is presented by contact persons of the participating institutions. In this way, researchers are encouraged to exchange ideas and share experiences with existing projects.
DARIAH-DE publications on the topic
A detailed discussion on copyright and recommendations for standard licenses for research data can be found in the DARIAH-DE Working Papers:
-
Nikolaos Beer, Kristin Herold, Maurice Heinrich, Wibke Kolbmann, Thomas Kollatz, Matteo Romanello, Sebastian Rose, Felix Falco Schäfer, Niels-Oliver Walkowski: "Datenlizenzen für geisteswissenschaftliche Forschungsdaten - Rechtliche Bedingungen und Handlungsbedarf". DARIAH-DE Working Papers Nr. 6. Göttingen: DARIAH-DE, 2014. URN: urn:nbn:de:gbv:7-dariah-2014-4-8
-
Paul Klimpel, John H. Weitzmann: "Forschen in der digitalen Welt. Juristische Handreichung für die Geisteswissenschaften". DARIAH-DE Working Papers Nr. 12. Göttingen: DARIAH-DE, 2015. URN: urn:nbn:de:gbv:7-dariah-2015-5-0
DARIAH-DE is committed to the transparent dissemination of digital research methods and the tools used for this, as they are, for example, recorded by DIRT. DARIAH-DE would like to contribute to the visibility - and also to the self-understanding - of the digital spiritual sciences. The creation of a SKOS-based taxonomy of DH procedures is an important step towards networking the research community and also for assigning and documenting the results achieved.

Fig. 1: An example of the relationship between tools, methods, and methods
For example, in a collaboration with NeDiMAH, a comprehensive ontology is being worked out, which will allow to construct a complex model for the relationship of research fields, methods, institutions and research data and results.
The described endeavor aims at a stronger formalization of our understanding of the digital humanities and can contribute to the development of a research infrastructure.

Fig. 2: A visualization of the TADiRAH taxonomy for the formalization of methods of digital humanities. Go to TaDiRAH on GitHub
The DARIAH-DE „Forschungsdaten-Föderationsarchitektur" (DFA) is the term for services and tools that enable research data and collection descriptions to be found from various sources, such as cultural institutions, libraries, archives, research facilities, and data centers, and used for analysis.
Search queries in a scientific context require high accuracy in the determination of the respective parameters. It should be possible for researchers to limit their scientific research in the digital environment to specific sources. In this way, XML structures can be interrogated from data sets of different provenances, thus ensuring the interoperability of different data and metadata schemata, as well as correlating heterogeneous data and metadata sources with a common reference for places, names, data, or other logical units.

Figure 1: Schematic structure of the DARIAH-DE Data Federation Architecture
The DARIAH-DE „Forschungsdaten-Förderationsarchitektur", visualized in the graph above, includes indexing and displaying research data, providing sustained and sustained access to the use of technical tools to compare descriptions and content of digital collections, and a Comprehensive search functionality for heterogeneously structured data collections and archives.
The DARIAH-DE Forschungsdaten-Förderationsarchitektur is modular and can be extended at any time by further components and includes the following tools and services at the moment :
In Collection Registry, information from research data collections can be detected in DARIAH-DE, as well as new collection information can be registered.
The DARIAH-DE Repository allows to save research data, provide it with metadata, make persistent, machine-readable referencing through the use of Persistent Identifiers, and find it through the generic search. It is also possible to use the repository to archive data collections in a sustainable and secure manner.
With the help of the DARIAH-DE Publikator, research data can be conveniently imported into the DARIAH-DE repository via graphical interface and awarded with metadata. These can then be entered into the collection registry as a collection and are then detected in the generic search.
The Data Modeling Environment (DME) is the place where data can be modelled and mappings between data models can be stored, managed on a long-term basis and combined as required. It thus provides conceptual support for researchers in the arts, humanities and social sciences to connect heterogeneous data and thus create interoperability.
Mappings allow automated translations of data from one model into another. Therfore, the DME forms the basis, for example, for the generic search of different collections. The functionality of the DME regarding mapping between data models is illustrated in the following screenshot of the user interface:
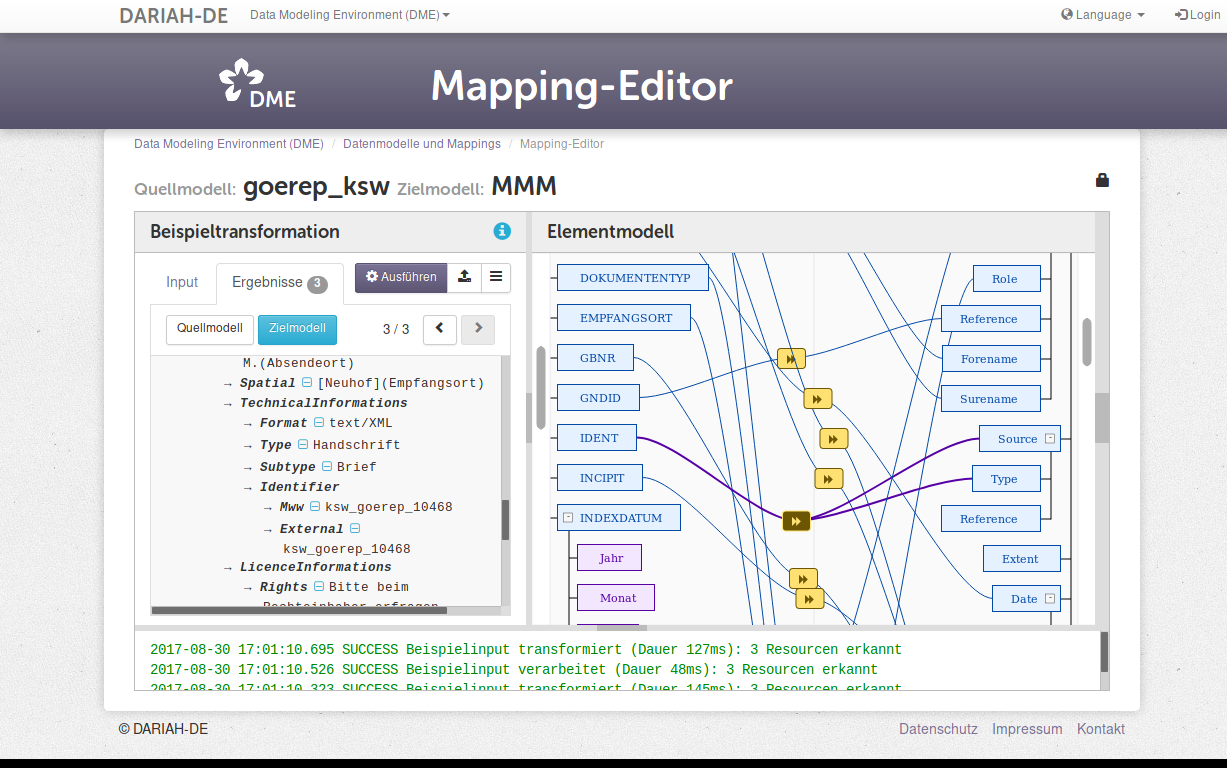
Figure 2: Crosswalk Mapping in the Data Modeling Environment.
The Generic Search provides a front-end for the data stored in the Collection Registry and the DARAH-DE repository. The generic search can be used to search the distributed data records. In addition, using the generic search, it is possible to search the listed metadata, save this search in a personalized way, and then adapt or refine it at a later date.
The Epic-PID Service provides as a basic service for the permanent referencing of the research data via so-called 'persistent identifiers'. The latter are services that ensure a sustainable reference to data. Thus, references, for example in scientific publications, remain stable even if the location of the referenced data changes. DARIAH-DE uses PIDs from the European Persistent Identifier Consortium (EPIC).
This set of digital tools is a modular software architecture that allows each service to access heterogeneous data sources of different origins. New methods for the analysis of distributed data collections are thereby obtained.